BigQuery Fundamentals for Software Developers and Integrating with Node.js
As a web/software application developer, you might encounter a situation where a data analyst approaches you and says, "Hey, we need some extra data in Google Analytics (or Looker Studio). We noticed that we can display charts with data from Google's BigQuery database. Could you send data from the checkout process to that database, so we can analyze it?"
If you haven't worked with BigQuery or a data warehouse before, what should you do?
I hope that you have an answer by the end of this guide. We'll mainly focus on BigQuery with Node.JS, but the first half of this guide covers BigQuery from a software developer perspective in general.
What is BigQuery?
BigQuery is a fully managed, cloud-based, data warehouse (DWH) provided by Google Cloud Platform (GCP) that enables users to store, process, and analyze massive datasets faster than your traditional database (e.g. MySQL).
Importing large datasets is integrated into BigQuery, especially from Google services such as Google Analytics and Google Ads, as well as third-party services like Amazon S3. Additionally, users can dump large datasets from various file types such as JSON, CSV, Avro, ORC, Parquet, and Firestore files into BigQuery, as explained in the documentation.
Data in BigQuery can be analyzed by writing SQL-like queries or using external services such as Google Spreadsheets, Looker Studio (Google's enterprise data visualization tool), and more.
For more information about BigQuery's architecture, visit this Google blog post.
1.0.0 - BigQuery Gotchas
Recap: DDL & DML
Both DDL and DML are subcategories of SQL.
Data Definition Language (DDL) consists of statements to specify and modify table schemas. DDL includes:
ALTER,COMMENT,CREATE,DROP,RENAMEandTRUNCATE.Data Manipulation Language (DML) consists of statements to insert, modify or delete data. DML includes:
INSERT,UPDATE,DELETE,LOCK,MERGEandCALL.
If you come from a traditional SQL background (e.g., MySQL, PostgreSQL, etc.), there are several important differences and gotchas to keep in mind while working with BigQuery:
BigQuery is a Data Warehouse, not your traditional application database like MySQL. (1)
Data warehouses are designed for reporting and analysis (online analytical processing, or OLAP), and to pull together large datasets from various sources. They're not meant for operational or transactional purposes (online transaction processing, or OLTP) like MySQL powers applications with a mix of CRUD queries.BigQuery is a column-oriented database, not a row-oriented one like MySQL. (1, 2)
In a row-oriented database, all related data is stored together, such as the values of a single user:name="Jerry"+age=25+email="jerry@example.com". In contrast, in a column-oriented database, all data of the same attribute is stored together, such asage=25(Jerry) +age=32(Marie) +age=17(Peter). This makes aggregating data across many records much more performant.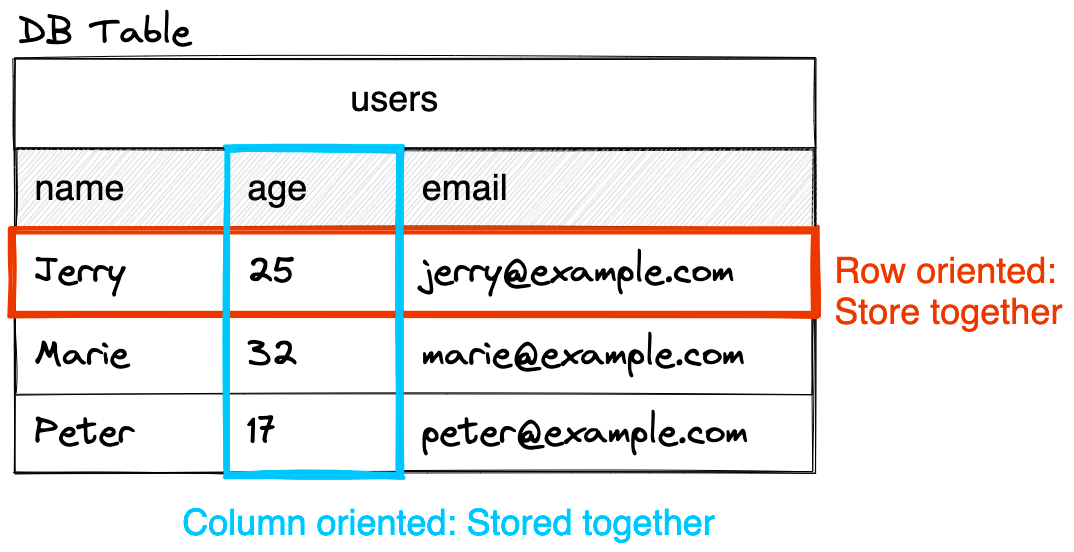
BigQuery Table Design should use denormalization, not normalization.
In database design, normalization means organizing data by dividing it into smaller, related tables and defining relationships between them to eliminate data redundancy (duplicates) and improve data consistency. However, BigQuery uses denormalization, which combines data from multiple tables into a single table with nested fields to reduce the number of joins required to retrieve data. This intentionally violates normalization rules by including duplicated data, but it improves query performance. BigQuery uses internally the Nested and repeated fields schema model, which is different from more advanced data warehouse schema models like the Star schema and Snowflake schema model.BigQuery is supposed to be used for bulk updates, also known as load jobs. (1)
Avoid inserting one row at a time, as this means you're likely treating BigQuery as a traditional database. Have a look at the "Using BigQuery with a Web/Software Application"section further below, where we talk about what you probably came here for.
If you still require frequent single-row inserts, use streaming.
Streams are a powerful way of piping data through as it comes in (in chunks), rather than all at once, even for smaller datasets. While MySQL and PostgreSQL support streaming too, this is rather an edge case than commonly used. Therefore, it's recommended to use the BigQuery client libraries that use streams for inserts. Streaming inserts have limitations and are bound to quotas.Query Quota Limits.
BigQuery operates on a serverless model, which means its resources are shared among many users and represented by virtual CPU units called "Slots". Queries can utilize multiple slots, but you can only use an X number of slots at any given time. Regardless of slot restrictions, additional query limitations are also in place to ensure fair usage and prevent excessive slot consumption (e.g. preventing abusers from using up all X slots, 24/7 a day) (1). The following restrictions are only concerned with query limitations, not slots.Streaming Inserts: You cannot modify data with
UPDATE,DELETE, orMERGEfor the first 30 minutes after inserting it using streamingINSERTs. It may take up to 90 minutes for the data to be ready for copy operations. Streaming inserts are limited to 50,000 rows per request.(1, 2)Jobs: Jobs are actions that BigQuery runs on your behalf to load data, export data, query data, or copy data. After 1500 jobs a day (or streaming inserts), all jobs will stop working except query jobs & streaming inserts, which have no limitations (1, 2, 3).
BigQuery charges by usage, not by instance.
BigQuery is an on-demand, serverless data warehouse that charges by usage. When you make a request, it spins up, executes the request, provides the result, and spins down. You are charged based on how much data is processed, unlike traditional cloud-based and managed database services like GCP Cloud SQL, where you are charged for every minute the instance is active. For example, the smallest Cloud SQL for MySQL instance costs $9/month.Prefer table partitioning over sharding. (1, 2)
A partitioned table is a single table divided into segments, called partitions, that make it easier to manage and query your data. You can specify whether a table should be partitioned when creating it. Sharding, on the other hand, involves having two or more tables with the same schema & prefix, and suffix of the form_YYYYMMDD, such asposts_20150101andposts_20220101. BigQuery treats these tables as a group and displays them in the GCP BigQuery website with a dropdown that allows selecting the shard.Careful choosing your SQL query.
A column-oriented database processes data differently, which can quickly lead to expensive bills.Be aware of expensive
SELECTstatements, even with aLIMITclause (1, 2, 3). BigQuery charges you according to the data processed in the columns you select, even if you set an explicitLIMITon the results, which only improves speed but doesn't change the amount of processed data. Running aSELECT * FROM birdy_posts LIMIT 10can quickly result in excessive charges on large tables. At the time of writing, 1 TB query processing costs $5. Imagine the costs of a single query on a petabyte table.Use
EXISTS()instead ofCOUNT(), because the former stops processing as soon as it locates the first matching row, whereasCOUNT()scans the entire table.Consider using
SEARCH()for nested string data instead ofWHERE(1, 2, 3). Google recently released the built-inSEARCHfunction, which simplifies data finding, even in buried JSON structures, and reduces processing overhead.
BigQuery simplifies integer data types with a single
INT64implementation.
In contrast to traditional databases that offer various integer types with different sizes (such asINT,SMALLINT,INTEGER,BIGINT,TINYINT,BYTEINT), BigQuery streamlines its data type system by providing only one integer data type:INT64. You can still use any of the other integer data types mentioned, as they simply serve as aliases toINT64.
BigQuery is a rapidly evolving tool, and new features are added frequently. For example, in late 2022, transaction capabilities were introduced (Feature Request and Documentation). In early 2023, Google also added primary and foreign key features to BigQuery, but these are only used to speed up queries and do not enforce constraints to prevent duplication. This means that duplication prevention must be handled manually. It's important to research specific topics and needs, as there may be new solutions available.
1.1.0 - Using BigQuery with a Web/Software Application
As mentioned earlier, BigQuery (OLAP) is specifically designed to process massive amounts of data. In contrast, traditional databases like MySQL (OLTP) are better suited for web/software applications that require frequent small read/write operations, as they are optimized for real-time data management.
Directly connecting your web/software application to BigQuery may lead to treating it like a traditional database, which is not advisable since it is not optimized for small inserts. Instead, you should collect your data, group it, and then hand it over to BigQuery. This can be done in several ways:
1.1.1 - GCP Cloud SQL
GCP Cloud SQL is GCP's managed MySQL, PostgreSQL, or SQL Server database service. You can directly query for Cloud SQL data from BigQuery using federated queries. This allows you, for example, to connect to a MySQL database for making your small read/write operations, but with BigQuery having access to the dataset.
1.1.2 - Change Data Capture (CDC) Platform
A Change Data Capture (CDC) platform connects to a data source, such as a MySQL database, and listens for various database events, such as inserts, updates, and deletes. It then sends these data changes to a data warehouse like BigQuery in bulk periodically, where they end up being stored.
There are many CDC platforms available, such as CDC as a service, which includes Fivetran (1,2) or GCP Datastream. Self-hosted solutions like Debezium are also available.
1.1.3 - Group Data and Send in Bulk
You can manually collect and group data from your web/software application and then send it periodically to BigQuery without temporarily storing it in a traditional database like MySQL.
This can be done with:
Worker Threads: For example, Worker Threads in Node.js can offload operations from the main thread on which the app runs. Whenever new data has to be collected, you can send it to the worker thread, which then performs a bulk insert every X seconds. Implementing worker threads in Node.js can be challenging (1), so you might want to read this article first. Alternatively, you can run the worker thread in lower-level languages such as C or more modern compiled languages like Go or Rust for maximum performance.
Message Broker: A message broker like RabbitMQ allows you to collect and group data from the application that you would otherwise send to a database. You can then periodically send the grouped data to BigQuery.
Implementing your own solution with worker threads or a message broker requires you to know how to use and connect to BigQuery in your application. Below, we will show how to set up BigQuery and connect to it in Node.js.
2.0.0 - BigQuery Setup
For the course of this guide, we're connecting BigQuery to our imaginary "Birdy" application, a Twitter clone.
2.1.0 - About Application environments
When working with software applications, it's common to have multiple environments like test, staging, and production. These environments allow new features to be tested without affecting the production data. In GCP, you can isolate these environments using "Projects" (known as "Resource Groups" in Azure). Projects enable you to group all resources of an environment in one place and isolate production data from test data.
However, depending on your need for BigQuery, this may not be necessary. For instance, if BigQuery is only used for data engineering/analytics, while the rest of the software application runs in AWS, it's common to run tests and production data in the same "Project", on the same BigQuery instance, but separated by BigQuery datasets (a container for tables). For example, birdy_test and birdy_production. This approach eliminates operational overhead for analytics teams that may need to connect tools to BigQuery since they only need to connect to one project instance instead of several ones. Additionally, they can test data transformations before using production data.
It can therefore be challenging to find multi-environment good practices online, especially for data warehouses like BigQuery, which allow easy Looker Studio integration. Hence, you should choose the requirement that you and your team feel most comfortable with.
In my case, the entire Birdy application is hosted in GCP, and we use a "Project" per environment.
Note
The numbers in the following images do not represent the step they refer to. They serve as visual guidelines on their own.
Below, I'll quickly demonstrate how to create a new "Project" called birdy_test.
Click on the Project dropdown.
Click on the "NEW PROJECT" button.
Create a new project for each environment. Here we're only showing
birdy-test, but you should also create projects forbirdy-stagingandbirdy-production.
Switch to the
birdy-testProject by selecting it from the Project dropdown list.
The guide continues with birdy-test "Project per environment" approach, but creating a dataset per environment is a straightforward process after you understood the basics.
2.2.0 - Service accounts and IAM
2.2.1 - What is a Service Account and IAM in Google Cloud Platform?
A Service Account in GCP is an identity used by an application to connect with a GCP service or run API requests. A Service Account is associated with some Identity and Access Management (IAM) rules that grant permissions and roles to use specific GCP services like BigQuery or Google Cloud Storage.
2.2.2 - How to authenticate with a Service Account
An application can only authenticate with a Service Account using a private and public RSA key pair. Authentication credentials, comprising the key pairs and other necessary authentication values, can be generated and exported as a JSON file using the GCP website.
2.2.3 - Creating a Service Account
Below are the steps to create a new GCP Service Account with the authentication credentials for BigQuery.
Open the GCP Sidebar, then hover over "IAM and admin" and click on the "Service accounts" product. If "Service accounts" is not visible, you can as well find it on the "IAM and admin" page.
On the "Service accounts" page, click on the "+ CREATE SERVICE ACCOUNT" button.
Fill in the required details. Google has a recommended naming convention for Service Accounts, but we chose to name ours
birdy-testto make it more obvious which environment we're connected to. The "Grant this service account access to project" and "Grant users access to this service account" options allow for user management and can be modified later, which we skip for now.
After creating the service account, click on the three dots to open the actions dropdown list and click on "Manage keys."
On the key page of your selected service account, click on the "ADD KEY" dropdown list and select "Create new key."
In the modal that appears, ensure that JSON is selected and click on "CREATE."
After creating the key, the authentication credentials will be automatically downloaded as a JSON file.
The content of the file will look something like this:
{
"type": "service_account",
"project_id": "birdy-test-382808",
"private_key_id": "ce27qq5c124ced34e25f9efbf4556d3959d69de4",
"private_key": "-----BEGIN PRIVATE KEY-----\nMIIE...oucZfA==\n-----END PRIVATE KEY-----\n",
"client_email": "birdy-test@birdy-test-382808.iam.gserviceaccount.com",
"client_id": "109053470252784434641",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/birdy-test%40birdy-test-382808.iam.gserviceaccount.com"
}
To ensure the security of this file, please treat it with the same level of confidentiality as you would a password. Avoid moving it into any directory shared with cloud storage such as iCloud, Dropbox, OneDrive, etc. Additionally, do not commit this file to a git repository. We're solving this issue later by converting them into environment variables.
2.2.4 - Adding IAM permissions to your Service Account
Before we can use the authentication credentials from the JSON, we first must grant our Service Account access to BigQuery. Below are the steps to add GCP IAM rules to a GCP Service Account.
Go to the "IAM and admin" product page and click on the "IAM" navigation menu in the sidebar.
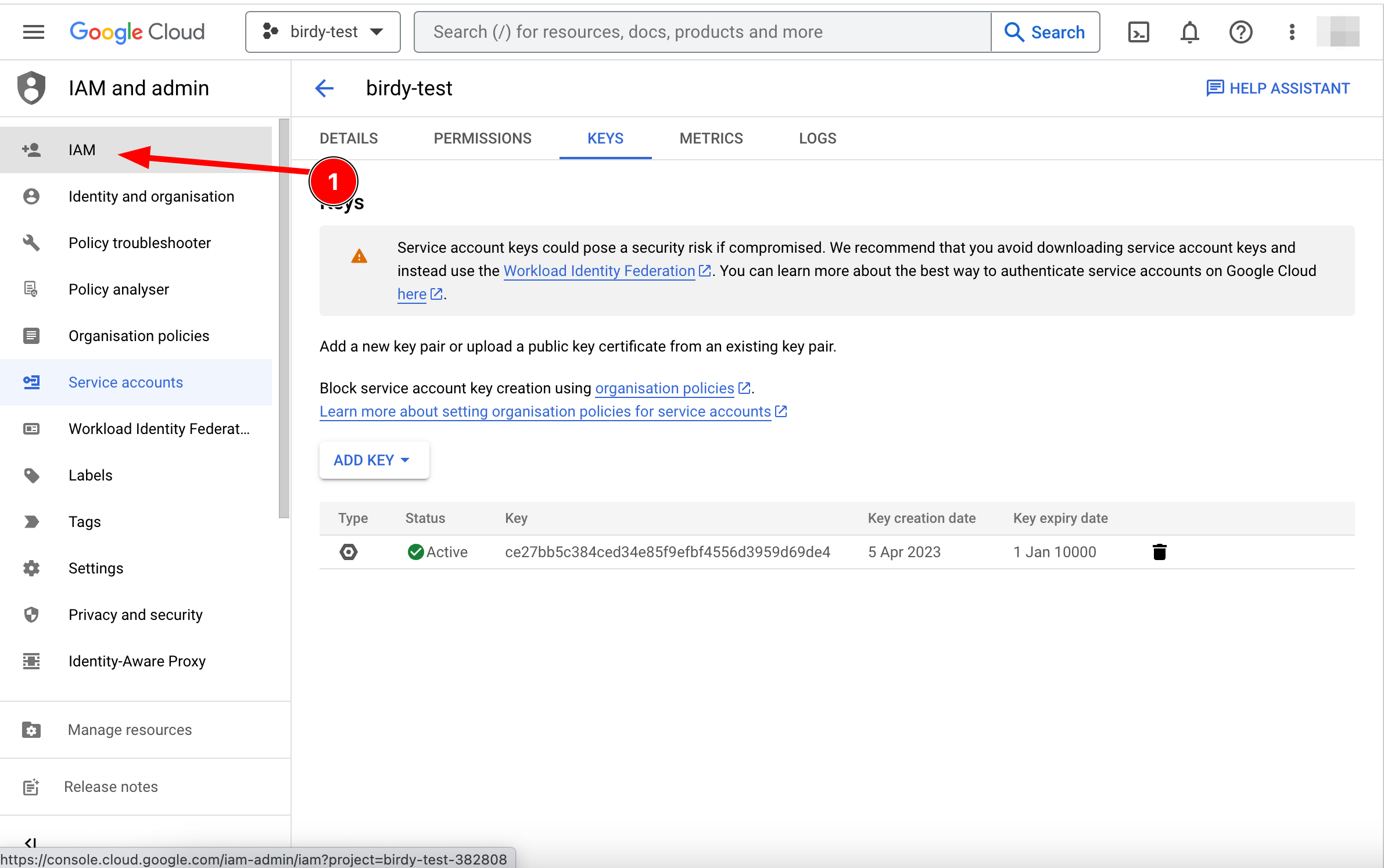
On the "IAM" page, click on the "+ GRANT ACCESS" button.
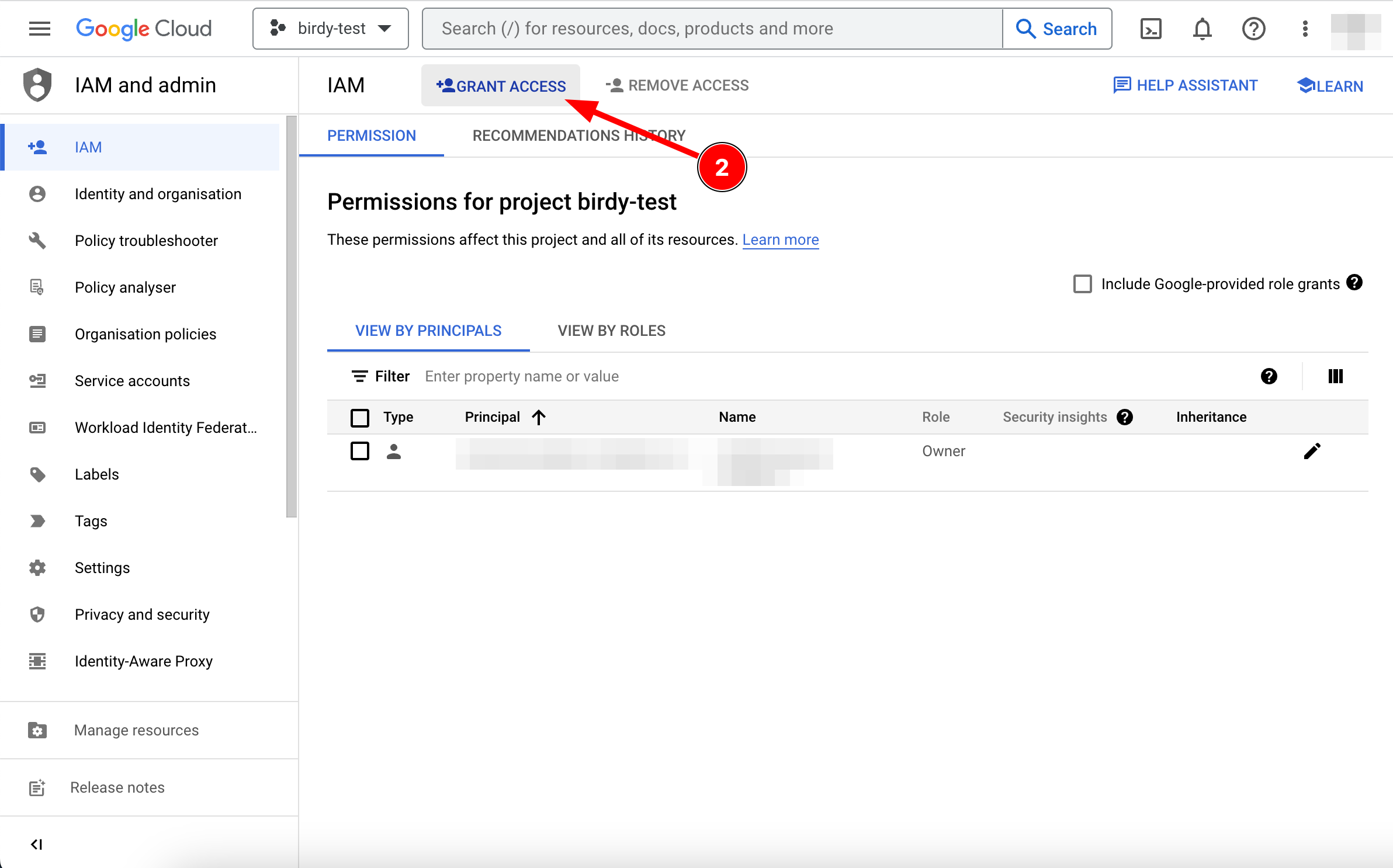
In the "Grant access" window that appears, select your Service Account email. You can find it by searching for it in the input field, from the downloaded JSON file, or by inspecting the service account from the "Service Accounts" page on the GCP website.
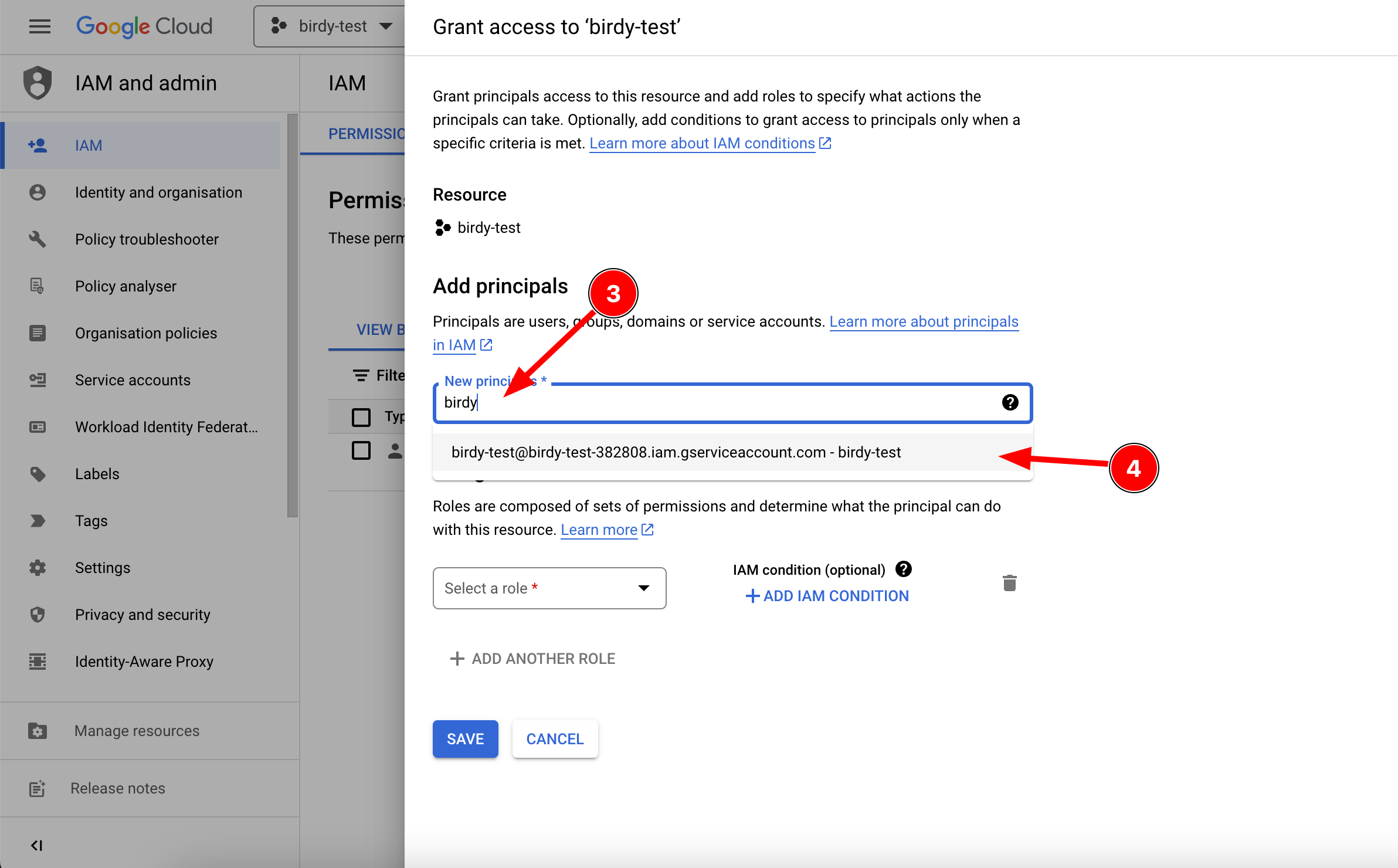
Next, add the IAM permission using the "Select role" dropdown list in the "Assign Roles" section. For starters, we recommend selecting "BigQuery Data Editor" and then fine-tuning permissions as necessary.
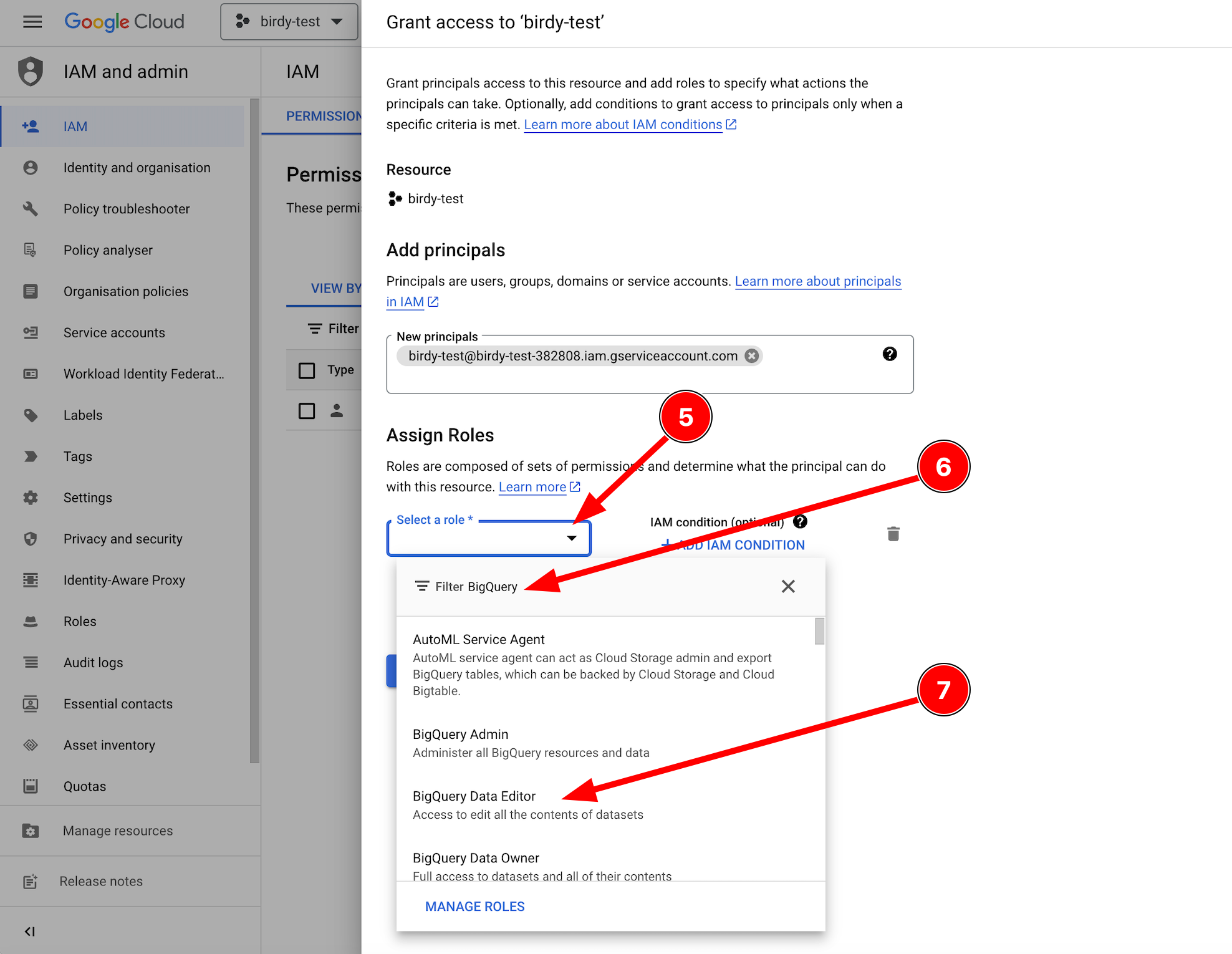
Click the "SAVE" button to finish.
Now, your Service Account has the necessary permissions to access and query BigQuery within your birdy-test Project.
Note: Billing
Please ensure that billing is enabled for your GCP Project before attempting to connect to BigQuery with your Service Account, as some projects may not have billing enabled. Without billing, you won't be able to connect.
3.0.0 - Using BigQuery
3.1.0 - Connecting to BigQuery in Node.js
Google suggests that you connect to BigQuery using the JSON file. While this may work, it presents a security concern. You never want to commit files with authentication credentials to your git repository. Instead, we should use them as environment variables with the help of for example dotenv. The following steps expect that you have dotenv installed (or some sort of environment variable loader) in your project.
Install the BigQuery client library
npm install @google-cloud/bigqueryCreate a new file that you use as your global BigQuery config file which connects to BigQuery and exports an instance that can be used in your application. We will use
./bigquery.jsfor the next steps.Copy & paste the content of the authentication credentials JSON file into the file, as a JavaScript object.
// ./bigquery.js const credentials = { type: "service_account", project_id: "birdy-test-382808", private_key_id: "ce27qq5c124ced34e25f9efbf4556d3959d69de4", private_key: "-----BEGIN PRIVATE KEY-----\nMIIE...oucZfA==\n-----END PRIVATE KEY-----\n", client_email: "birdy-test@birdy-test-382808.iam.gserviceaccount.com", client_id: "109053470252784434641", auth_uri: "https://accounts.google.com/o/oauth2/auth", token_uri: "https://oauth2.googleapis.com/token", auth_provider_x509_cert_url: "https://www.googleapis.com/oauth2/v1/certs", client_x509_cert_url: "https://www.googleapis.com/robot/v1/metadata/x509/birdy-test%40birdy-test-382808.iam.gserviceaccount.com", };Move the following values to your
.envfile and update yourbigquery.jsfile to use the environment variables instead:project_id→process.env.BIGQUERY_PROJECT_IDprivate_key_id→process.env.BIGQUERY_PRIVATE_KEY_IDprivate_key→process.env.BIGQUERY_PRIVATE_KEYclient_email→process.env.BIGQUERY_CLIENT_EMAILclient_id→process.env.BIGQUERY_CLIENT_IDclient_x509_cert_url→process.env.BIGQUERY_CLIENT_X509_CERT_URL
Connect to BigQuery and export the instance.
// ./bigquery.js const { BigQuery: GBigQuery } = require("@google-cloud/bigquery"); // import as alias require('dotenv').config() const credentials = { type: "service_account", project_id: process.env.BIGQUERY_PROJECT_ID, private_key_id: process.env.BIGQUERY_PRIVATE_KEY_ID, private_key: process.env.BIGQUERY_PRIVATE_KEY, client_email: process.env.BIGQUERY_CLIENT_EMAIL, client_id: process.env.BIGQUERY_CLIENT_ID, auth_uri: "https://accounts.google.com/o/oauth2/auth", token_uri: "https://oauth2.googleapis.com/token", auth_provider_x509_cert_url: "https://www.googleapis.com/oauth2/v1/certs", client_x509_cert_url: process.env.BIGQUERY_CLIENT_X509_CERT_URL, }; const bigquery = new GBigQuery({ credentials, }); module.exports = { bigquery };
You're now ready to use BigQuery in your application.
3.2.0 - Creating a dataset
A dataset in BigQuery is comparable to a MySQL database. Similarly, you can create several datasets in BigQuery, just as you can have multiple databases in a MySQL instance. To create a dataset in BigQuery, you need to specify a schema using Data Definition Language (DDL) statements, such as CREATE, ALTER, and DROP.
There are several ways to create a dataset in BigQuery:
Point and click approach: You can create a dataset easily using the GCP BigQuery website by selecting "Create dataset" from the dropdown menu after clicking on the three dots of your BigQuery instance. This method allows you to create a dataset without much SQL knowledge.
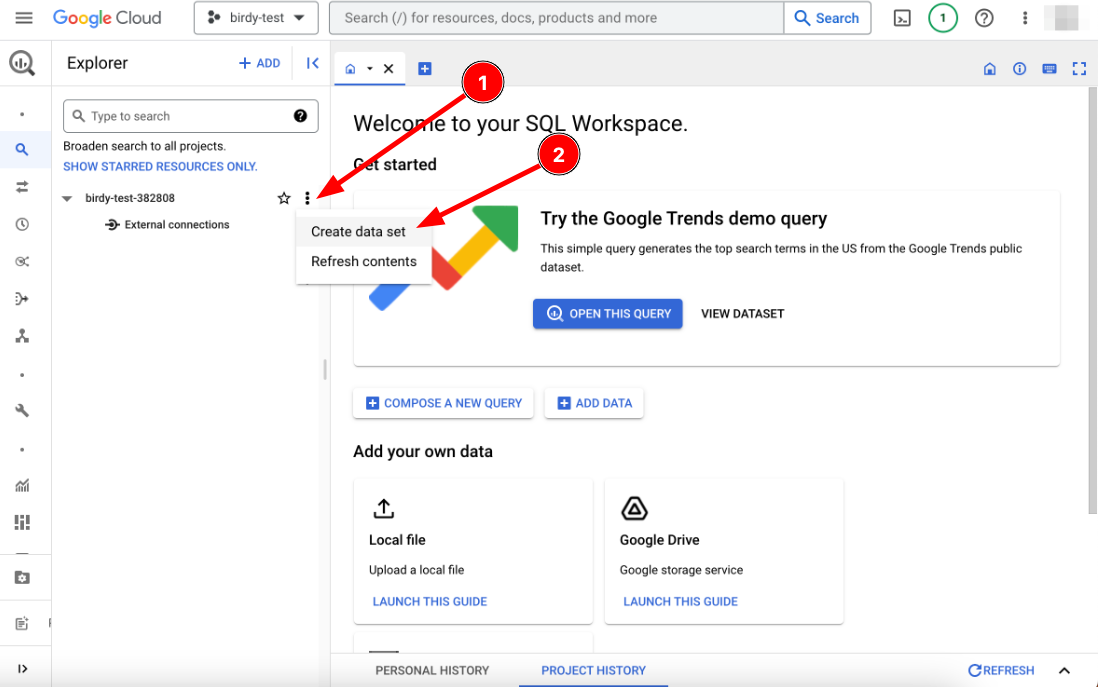
Writing an SQL query: You can also create a dataset by writing an SQL query in the GCP BigQuery website. It's important to specify the project you want to create the dataset in by separating them with a dot and encapsulating them with a backtick, for example:
CREATE TABLE `birdy-test-382808.birdy_posts` (...)
Using a BigQuery client library: You can also create a dataset using a BigQuery client library such as Node.js:
const bigquery = require("./bigquery"); async function createDataset(){ await bigquery.createDataset("birdy_posts", options); } createDataset();
3.3.0 - Creating a table
To create a table in BigQuery, you need to specify a schema using Data Definition Language (DDL) statements.
There are several ways to create a table in BigQuery:
Point and click approach: You can create a table easily using the GCP BigQuery website by selecting "Create Table" from the dropdown menu after clicking on the three dots of a data set. This method allows you to create a table without much SQL knowledge.
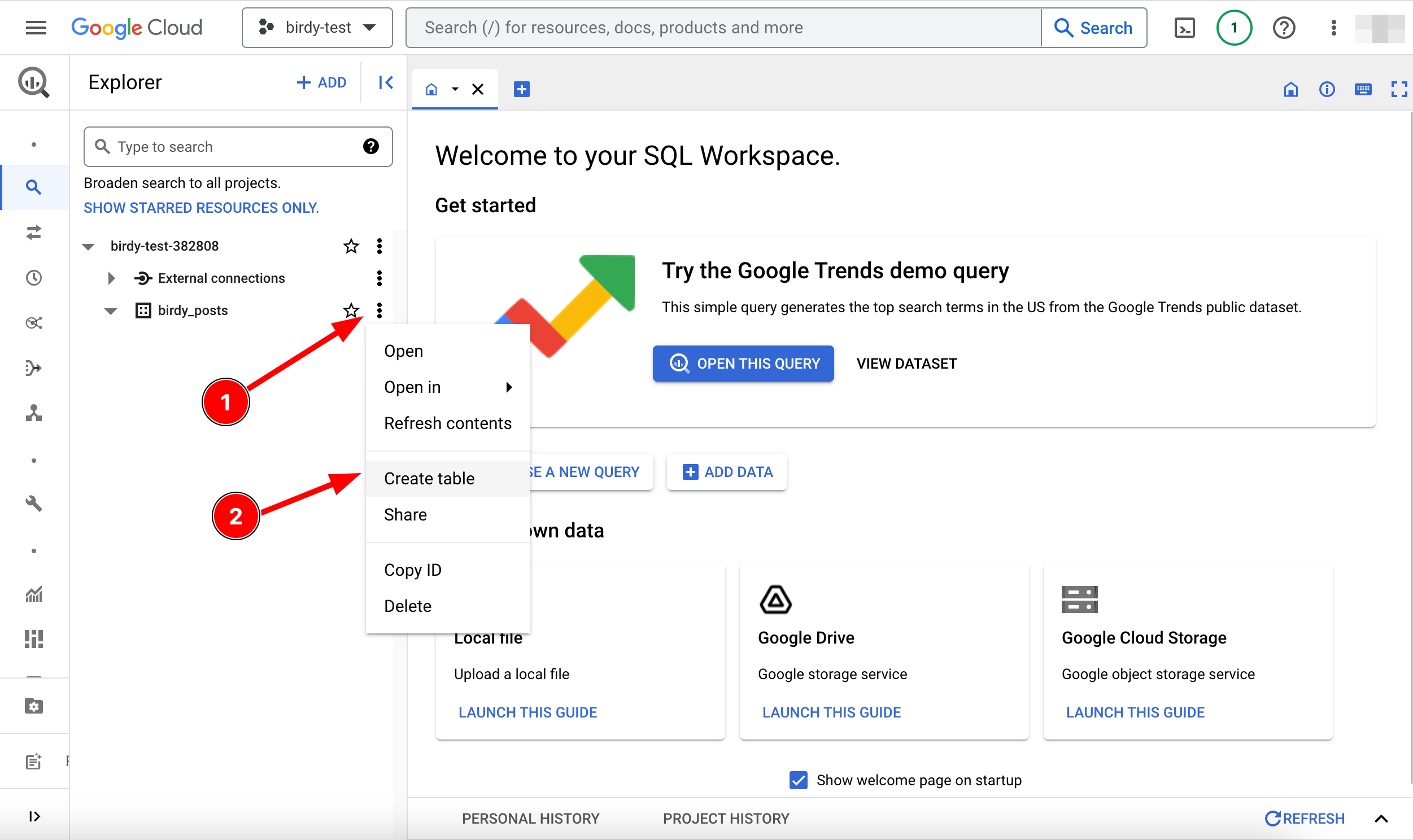
Writing an SQL query: You can also create a table by writing an SQL query in the GCP BigQuery website. It's important to specify the dataset you want to create the table in by separating them with a dot and encapsulating them with a backtick, for example:
CREATE TABLE `birdy_posts.my_new_table` (...)Using a BigQuery client library: You can also create a table using a BigQuery client library such as Node.js:
const bigquery = require("./bigquery"); async function createTable(){ const options = { schema: [ { name: "name", type: "STRING" }, { name: "age", type: "INTEGER" }, ], }; await bigquery .dataset("birdy_posts") .createTable("my_new_table", options); }
From my experience as a software application developer, you make changes to your tables over time. Manually managing these changes in a multi-environment architecture can be challenging, depending on their frequency and magnitude. In such cases with traditional databases, you would use automated schema migrations tools, which help you version database schemas and allow you to roll back changes if necessary.
3.4.0 - Schema Migration
To be perfectly clear, when talking about migration, we're referring to Schema Migration, which refers to the management of version-controlled, incremental and reversible changes to database schemas, not data migration which is the process of transferring data from one source to another. Your BigQuery setup could look like one of the following two:
You have the
birdy_test,birdy_staging,birdy_productionprojects, with each their own replication of tables in one dataset.You have one project (
birdy) but where the environments are separated by datasets (e.g.,birdy.birdy_test,birdy.birdy_staging,birdy.birdy_production) and each dataset has the same tables.
After spending a good amount of time researching and asking in several forums about how to best manage schema changes to tables, I came to the following conclusions:
In the case of data warehouses, schema changes and data transformation are typically handled by ETL (Extract, Transform, Load) processes that integrate data from various sources. This reduces the need for dedicated schema migration tools. For example, ETL are main features of Fivetran and GCP Datastream.
BigQuery allows for more flexible data types, and you maybe don't need schema migration (tools) at all. For the few times when you then would need it, you just run the SQL query against the table manually.
There may be situations where you want schema migration. Flyway and Liquibase are database schema migration tools that run on Java. While some can be used as standalone CLI's without a Java runtime (Flyaway), both require a Java Database Connectivity driver (JDBC driver) to connect to BigQuery.
3.4.1 - Schema migration tools
Although both Flyway and Liquibase offer limited open-source versions of their enterprise product, adding such tools to a non-Java runtime can be cumbersome. Unfortunately, I have not found any alternatives specifically for Node.js. I ended up installing both Flyway and Liquibase and analyzed the queries they made to BigQuery and the steps they performed during migration. I noticed that they used migration locks, which can also be found in various frameworks (Laravel for PHP, ASP.NET) and database libraries (Knex.js for Node.js). Locks ensure that migrations are executed safely and consistently, especially in a concurrent environment where multiple processes or threads might attempt to perform migrations simultaneously. The lock prevents race conditions and ensures that only one migration process runs at a time.
I have worked with migrations using locks many times, so I created my own Node.js BigQuery schema migration package, called @advename/bq-migrate, without any Java or JDBC dependencies. However, it's essential to avoid using streaming queries like .insert() for migrations. Instead, use the .query() method with SQL due to the streaming limitations discussed at the beginning of this guide. Have a look at the different supported DDL statements available for modifying table schemas
Note: This guide is not an advertisement for my migration library. I actually created it after I started writing this guide.
4.0.0 - Wrapping up
I hope this guide sheds light on what BigQuery is and how it should be used, specifically from the perspective of software developers or traditional database users.
Acknowledgements
I would like to thank the people at /r/dataengineering for their help and support.